Credit Risk Prediction
Data Modeling
The Credit Default Prediction project aims to develop a predictive model that determines whether a credit card customer will default on the next bill payment. This analysis holds significant importance for financial institutions seeking to assess credit levels accurately and set appropriate credit limits.
By leveraging payment history and demographic information like gender, age, education level, and marital status, the predictive model intends to aid in credit score calculation and risk management for clients.
Observation & Findings:
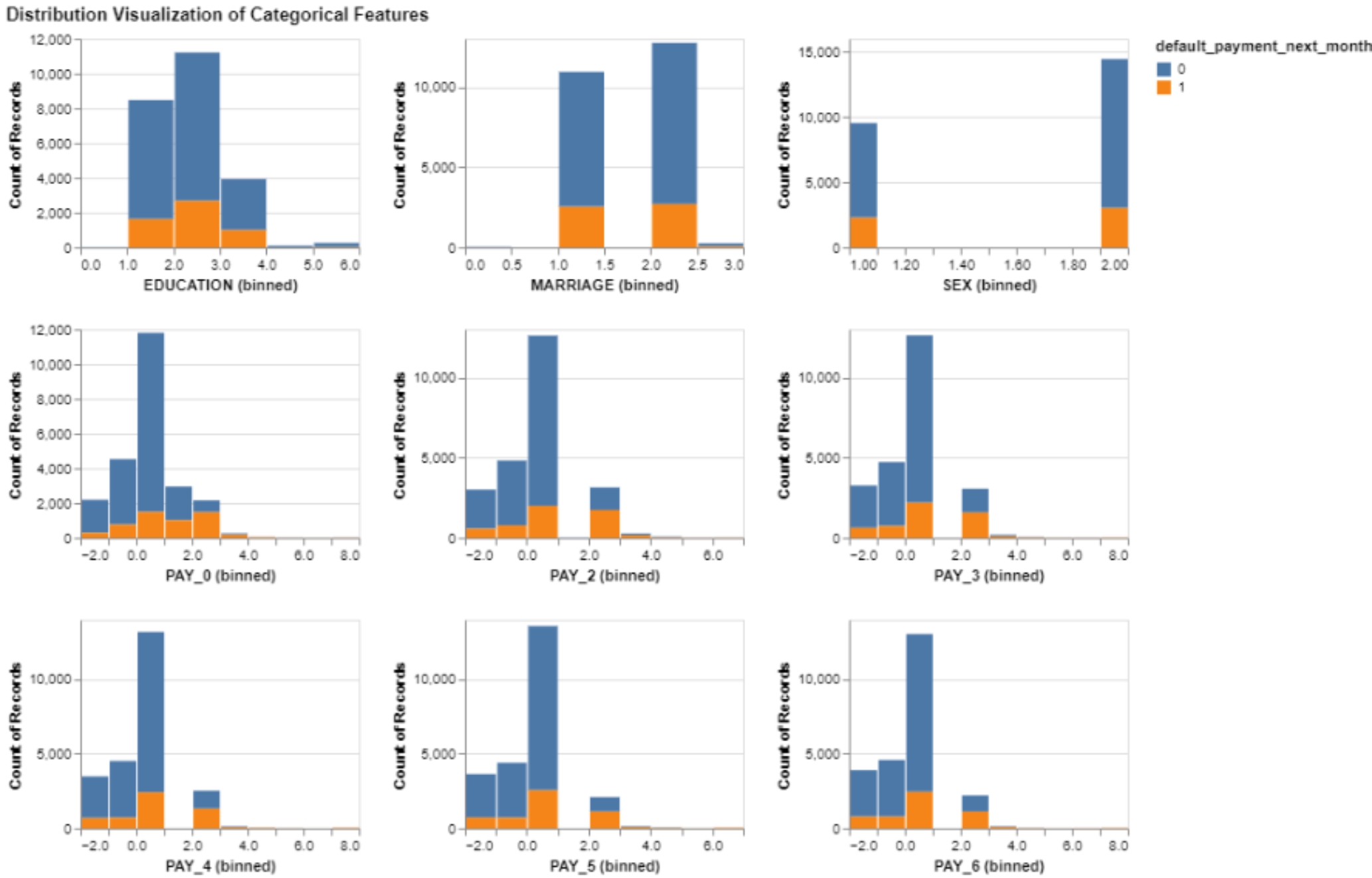
Data Overview: The dataset comprises 30,000 observations with 23 features and a binary target indicating default payment (1 for yes, 0 for no). It includes payment history over the past six months, monthly bill statements, payment statuses, payment amounts, credit amount, gender, education, marital status, and age.
Numerical Feature Distributions: The histograms depict the distribution of numerical features for both target classes. Notably, both classes exhibit similar distributions across features, suggesting a challenge due to class imbalance. The numeric features display a right-skewed distribution, which should be considered during model training.
Categorical Feature Distributions: Bar plots illustrate the distributions of categorical features segregated by target classes. The challenge in discerning feature importance arises due to class imbalance, making it challenging to identify key features from these plots.
Correlation Matrix Insights: The correlation matrix reveals strong correlations among certain features. For instance, 'PAY_0', 'PAY_2', 'PAY_3', 'PAY_4', 'PAY_5', and 'PAY_6' exhibit high intercorrelation, as do 'BILL_AMT1', 'BILL_AMT2', 'BILL_AMT3', 'BILL_AMT4', 'BILL_AMT5', and 'BILL_AMT6'. Such high correlations among these groups suggest potential multicollinearity issues, indicating the need for feature selection or dropping highly correlated pairs to enhance model performance.